آموزش تخصصی آمار و مدلسازی معادلات ساختاری
آزمون ها و روش های آماری متعدد و متنوع هستند و متناسب با نوع پژوهش، فرضیه ها و ابزار اندازه گیری و . باید اقدام به انتخاب روش آماری مناسب نمود. در کنار این امر، آشنایی با چگونگی کار با نرم افزارهای آماری (SPSS-LISREL-AMOS-Smart PLS) به خصوص در آزمون های پیشرفته نیز حائز اهمیت است. همچنین یکی از مواردی که شاید در ابتدای امر چندان مهم به نظر نرسد (اما در واقع مهم ترین بخش یک کار آماری است)، توانایی تفسیر و تحلیل نتایج آماری و ارائه یک گزارش آماری مناسب و قابل قبول اساتید است.
قطعا همه پژوهشگران با همه نرم افزارهای آماری یا روش های آماری آشنا نیستند و در پژوهش های متنوع خود در پی کسب مهارت های لازم در زمینه نرم افزارها و روش های آماری هستند. مراجعه به کتب و مقالات آموزشی یک از راه های آشنایی است اما معمولا حل مسائل خاص آماری، با استفاده از کتاب و مقالات زمان بر بوده و وقت زیادی را می گیردو مهم تر از آن معمولا مسائل خاص آماری به دلیل پیچیدگی و یا کاربردهای خاصی که دارند عموما به شیوه روان و قابل فهمی در کتب آماری ارائه نمی شود و در این زمان یا پژوهشگران باید با آزمون و خطا و صرف زمان زیاد مشکل آماری خویش را حل کنند یا به کلاس های آموزشی بروند و یا با افراد مطلع و مسلط به آزمون ها و روش های آماری م کنند.
مشخصات
از زمانی که روش حداقل مربعات جریی مورد توجه و استفاده پژوهشگران در رشته های مختلف مدیریتی مانند مدیریت استراتژیک، مدیریت بازاریابی و مدیریت سیستم های اطلاعات قرار گرفته است، تا به حال یک چالش هنوز پیش روی محققین قرار داد که مطالعات زیادی نیز درباره آن انجام نشده است. این موضوع همان ناهمگنی داده ها(heterogeneity) است که باعث گردیده تا یک قسمت به طور مجزا در نرم افزارهای PLS به این موضوع اختصاص یابد.
به طور نمونه در نرم افزار Smart PLS قسمتی با نام FIMIX-PLS در منوی Calculate قرار داد. در حقیقت روش های تحلیل آماری از جمله PLS، فرض می کنند که داده های گردآوری شده برای تحلیل از یک جامعه آماری مشخص انتخاب می شوند در حالی که این فرض غیر واقعی بوده و نرم افزارهای تحلیل آماری در نسخه های جدیدتر به این موضوع توجه وییه ای کرده اند.
ناهمگنی به این موضوع اشاره دارد که ممکن است داده های رسیده به دست پژوهشگر همگی از یک جنس و از یک خانواده نباشند. بنابراین تحلیل آنها تحت یک گروه درست نیست زیرا نتایجی که بدست خواهد آمد دقیق نیست و محقق را دچار اشتباه و سردرگمی در تفسیر نتایج می سازد.
درباره اهمیت توجه به ناهمگنی داده ها محققین زیادی اطهار نموده اند. ویلیامز و همکاران(2002) ادعا نموده اند که عدم توجه به موضوع ناهمگنی داده ها در دو قسمت مدلسازی معادلات ساختاری یعنی بخش مدل اندازه گیری و بخش مدل های ساختاری، محقق را دچار مشکل می سازد. در مطالعات مربوط به سنجش رضایت مشتری، جدیدی و همکاران(1997)، هان و همکاران(2002) و همچنین سارستد و همکاران(2009) نشان داده اند که نتایج تحلیل داده ها در مواقعی که تفاوت معناداری بین مقادیر تخمین زده شده در گروه های مختلف وجود دارد، می تواند گمراه کننده باشد.
بنابراین توجه به این موضوع و بررسی ناهمگنی داده ها بسیار حائز اهمیت است و پژوهشگرانی که از روش مدل سازی معادلات ساختاری استفاده می کنند باید برای اطمینان از اینکه تحلیل کل داده ها در تحقیق آنها تحت تاثیر ناهمگنی داده ها قرار نگرفته است، از این روش استفاده کرد و نتایج را گزارش دهند.
مشخصات
یکی از نرم افزارهای معادلات ساختاری که به بررسی آزمون فرضیات مربوطه می پردازد، نرم افزار pls می باشد. در سال 2005 توسط رینگل و همکاران وی در دانشگاه هامبورگ آلمان طراحی شده است. این نرم افزار قابلیت پردازش و تحلیل داده های خام را داراست. همچنین طراحی و آزمون مدل در آن به صورت کاملا گرافیکی انجام می شود. خروجی نرم افزار را می توان در قالب صفحات وب، اکسل و لاتکس مشاهده نمود.
از مدلیابی معادلات ساختاری با کمک روش حداقل مربعات جزیی و نرم افزار PLS، جهت آزمون فرضیات و صحّت مدل استفاده میشود. پیالاس نگرشی مبتنی بر واریانس است که در مقایسه با تکنیکهای مشابه معادلات ساختاری همچون آموس و- لیزرل شروط کمتری دارد. به طور مثال بر خلاف لیزرل، مدلیابی مسیر پیالاس برای کاربردهای واقعی مناسبتر است، به ویژه هنگامی که مدلها پیچیدهتر هستند، بهرهگیری از این نگرش مطلوبتر خواهد بود. مزیت اصلی آن در این است که این نوع مدلیابی نسبت به لیزرل به تعداد کمتری از نمونه نیاز دارد. محدودیت حجم نمونه ندارد و نمونه انتخاب شده می تواند برابر یا کمتر از 30 باشد، که در این صورت نتایج نیز معتبر است. همچنین به عنوان متدی قدرتمند مطرح میشود، در شرایطی که تعداد نمونهها و آیتمهای اندازهگیری محدود است و توزیع متغیرها میتواند نامعین باشد.
روش حداقل مربعات جزئی (PLS) یک راهکار جایگزین برای رگرسیون چندگانه و مدلسازی معادلات ساختاری مبتنی بر کوواریانس است. در حقیقت PLS اغلب بهعنوان یک روش معادلات ساختاری مبتنی بر مؤلفه (Component-Based SEM) یا معادلات ساختاری مبتنی بر واریانس (Variance-Based SEM) برخلاف روشهای مبتنی بر کوواریانس که توسط نرمافزارهای لیزرل، اموس انجام میگیرد، نامیده میشود. تحلیل PLS بر اساس مجموعهای از متغیرهای مستقل که بر مجموعهای متغیرهای وابسته تأثیر میگذارند، بکار گرفته میشود
روش PLS بهعنوان یک مدل رگرسیونی جهت پیشبینی یک یا چند متغیر وابسته از طریق مجموعهای از یک یا چند مؤلفه مستقل تعریف میشود و یا میتوان بهعنوان یک مدل مسیر جهت تفسیر تأثیرات متغیرهای مستقل بر متغیرهای وابسته (پاسخ) در نظر گرفت.
روش PLS بیشتر مواقع برای اهداف پژوهشی که از نوع مدلهای پیشبینی و اکتشافی است مناسب است. بهطورکلی مدلسازی معادلات ساختاری مبتنی بر کوواریانس در مواقعی که اهداف پژوهش از نوع مدلهای تأییدی (Confirmatory Modeling) است توصیه میشود. برخلاف مدل یابی معادلات ساختاری مبتنی بر کوواریانس که میزان برازش مدل مفروض را ارزیابی میکند و درنتیجه برآورد مدل در جهت تبیین، آزمون و تأیید نظریه است، روش PLS پیشبینی مدار بوده، به نظریه قوی نیاز ندارد و بهعنوان روش ساخت نظریه میتواند به کار رود.
از مزایای روش PLS میتوان به موارد زیر اشاره کرد:
– توانایی مدل کردن متغیرهای وابسته چندگانه بر اساس متغیرهای مستقل چندگانه؛
– توانایی کنترل هم خطیهای متعدد بین متغیرهای مستقل؛
– یک روش مقاوم در مقابل دادههای مفقودشده؛
– ایجاد متغیرهای پنهان مستقل تأثیرگذار بر متغیر (های) وابسته بهمنظور تعیین پیشبینی کنندههای قویتر.
نحوه تفسیر نتایج ضریب مسیر و مقدار آماره تی در نرم افزار smart pls
مدلسازی معادلات ساختاری به روش حداقل مربعات جزئی یا همان نرم افزار smart pls چند مدتی است که بعلت وجود مزیت های این نرم افزار بسیار مورد توجه محققین، اساتید و دانشجویان قرار گرفته است.وقتی از این نرم افزار استفاده می شود دو خروجی بسیار مهم و حیاتی وجود دارد.
۱- مقدار آماره تی
۲- ضرایب مسیر(بارهای عاملی)
اگر مقدار بارعاملی بین سوالات پرسشنامه و متغیرهای مکنون بیشتر از ۰٫۴ باشد نتیجه می گیریم که سوالی که برای آن سازه به کار برده ایم به خوبی متغیر مکنون مورد نظر را سنجیده است.مقدار آماره تی در واقع ملاک اصلی تایید یا رد فرضیات است.اگر این مقدار آمار به ترتیب از ۱٫۶۴ ، ۱٫۹۶ و ۲٫۵۸ بیشتر باشد نتیجه می گیریم که آن فرضیه در سطوح ۹۰، ۹۵ و ۹۹ درصد تایید می شود.همچنین باید گفت که اگر مقدار ضریب مسیر بین متغیر مکنون مستقل و متغیر مکنون وابسته مثبت باشد نتیجه می گیریم که با افزایش متغیر مستقل شاهد افزایش در متغیر وابسته خواهیم بود.و بالعکس اگر مقدار ضریب مسیر بین متغیر مکنون مستقل و متغیر مکنون وابسته منفی باشد نتیجه می گیریم که با افزایش متغیر مستقل شاهد کاهش در متغیر وابسته خواهیم بود
در محاسبه اثرات متغیر میانجی و تعدیلگر نیز می توان از این نرم افزار استفاده کرد.
هزینه انجام تحلیل آماری با SmartPLS به عوامل زیر بستگی دارد :
- تعداد فرضیه ها و پیچیدگی مدل
- تعداد متغیرهای میانجی
- تعداد متغیرهای تعدیلی
مشخصات
SmartPLS multigroup analysis: Chean, J./ Ramayah, T./ Memon, M.A./ Chuah, F./ Ting, H.:
PLS-SEM and future time perspectives: Chaouali, W./ Souiden, N./ Ringle, C.M.:
Predictive model selection test: Liengaard, B./ Sharma, P N./ Hult, G.T.M./ Jensen, M.B./ Sarstedt, M./ Hair, J.F./ Ringle, C.M.:
Prediction Metrics: Hair, J.F.:
No need for PROCESS: Sarstedt, M./ Hair, J.F./ Nitzl, C./ Ringle, C.M./ Howard, M.C.:
Weighted PLS-SEM (WPLS): Cheah, J.-H./ Roldán, J. L./ Ciavolino, E./ Ting, H./ Ramayah, T.:
PLS-SEM in Higher Education: Ghasemy, M./ Teeroovengadum, V./ Becker, J.-M./ & Ringle, C. M.:
Predictive model selection: Sharma, P.N./ Shmueli, G./ Sarstedt, M./ Danks, N./ Ray, S.:
Causal-predictive PLS-SEM: Chin, W./ Cheah, J.-H./ Liu, Y./ Ting, H./ Lim, X.-J./ & Cham Tat, H.:
Necessary condition analysis (NCA) and PLS-SEM: Richter, N.F./ Schubring, S./ Hauff, S./ Ringle, C.M./ Sarstedt, M.:
PLS-SEM results assessment: Sarstedt, M./ Ringle, C.M./ Cheah, J.H./ Ting, H./ Moisescu, O.I./ Radomir, L.:
Fit criteria: Cho, G./ Hwang, H./ Sarstedt, M./ Ringle, C.M.:
PLS-SEM and GSCA: Hwang, H./ Sarstedt, M./ Cheah, J. H./ Ringle, C.M.:
IPMA application in hospitality management: Nunkoo, R./ Teeroovengadum, V./ Ringle, C.M./ Sunnassee, V.:
More common factor issues: Rhemtulla, M./ van Bork, R./ Borsboom, D.:
Different views on CCA: Crittenden, V., Sarstedt, M., Astrachan, C., Hair, J., and Lourenco C. E.:
CCA: Hair, J.F./ Howard, M.C./ Nitzl, C.:
PLS-SEM and GSCA: Hwang, H./ Sarstedt, M./ Cheah, J.H./ & Ringle, C.M.:
PLS-SEM in HRM: Ringle, C.M./ Sarstedt, M./ Mitchell, R./ Gudergan, S.P.:
Common factor issue: Rigdon, E.E., Becker, J.-M./ Sarstedt, M.:
PLS-SEM software review: Sarstedt, M./ Cheah, J.-H.:
Higher-order models: Sarstedt, M./ Hair, J.F./ Cheah, J.-H./ Becker, J.-M./ Ringle, C.M.:
How to use PLSpredict?! Shmueli, G./ Sarstedt, M./ Hair, J.F./ Cheah, J.-H./ Ting, H./ Vaithilingam, S./ Ringle, C.M.:
PLS-SEM research networks: Khan, G.F./ Sarstedt, M./ Shiau, W.L., Hair, J.F./ Ringle, C.M./ Fritze, M.P.:
Some rethinking of the PLS-SEM rethinking: Hair, J.F. / Sarstedt, M. / Ringle, C.M.:
More on predictive model selection: Sharma, P.N./ Shmueli, G./ Sarstedt, M./ Thiele, K.O.:
PLS-SEM in marketing: Ahrholdt, D.C./ Gudergan, S./ Ringle, C.M.:
PLS-SEM in environmental management: Kotilainen, K./ Saari, U.A./ Mäkinen, S.J./ Ringle, C.M.
Something for PLS-SEM haters: Petter, S.:
Data from Experiments and PLS-SEM: Hair, J.F./ Ringle, C.M./ Gudergan, S.P./ Fischer, A./ Nitzl, C./ Menictas, C.:
Convergent valdity: Cheah, J.-H./ Sarstedt, M./ Ringle, C. M./ Ramayah, T./ Ting, H.:
Patient satisfaction: Rosenbusch, J./ Ismail, I.R./ Ringle, C.M.:
Endogeneity in PLS-SEM: Hult, G.T.M./ Hair, J.F./ Proksch, D./ Sarstedt, M./ Pinkwart, A./ Ringle, C.M.:
Moderation: Becker, J.-M./ Ringle, C.M./ Sarstedt, M.:
PLS-SEM in hospitality research: Ali, F./ Rasoolmanesh, S.M./ Sarstedt, M./ Ringle, C.M./ Ryu, K.:
PLS-SEM in finance: Avan, N.K./ Ringle, C.M. (20):
Handbook article on PLS-SEM: Sarstedt, M./ Ringle, C.M./ Hair, J.F. (2017):
Mediation: Cepeda Carrión, G./ Nitzl, C./ Roldán, J.L. (2017):
Segmentation: Sarstedt, M./ Ringle, C.M./ Hair, J.F. (2017):
CB-SEM and PLS-SEM: Rigdon/ E. E./ Sarstedt, M./ Ringle, C. M. (2017).
PLS-SEM performance: Hair, J.F./ Hult, G.T.M./ Ringle, C.M./ Sarstedt, M./ Thiele, K.O.
Prediction: Shmueli, G./ Ray, S./ Velasquez Estrada, J.M./ Chatla, S.B.
PLS-SEM: Richter, N.F./ Cepeda Carrión, G./ Roldán, J.L./ Ringle C.M.:
CB-SEM and PLS-SEM: Sarstedt, M./ Hair, J.F./ Ringle, C.M./ Thiele, K.O./ Gudergan, S.P.
Mediation: Nitzl, C./ Roldán, J.L./ Cepeda Carrión, G.:
Importance-performance map (IPMA): Ringle, C.M./ Sarstedt, M.:
Measurement invariance: Henseler, J./ Ringle, C.M./ Sarstedt, M.:
Weigthed PLS: Becker, J.-M./ Ismail, I. R.
FIMIX-PLS segmentation: Hair, J.F./ Sarstedt, M./ Matthews, L./ Ringle, C.M.:
FIMIX-PLS tutorial: Matthews, L./ Sarstedt, M./ Hair, J.F./ Ringle, C.M.:
Dynamic PLS: Schubring, S./ Lorscheid, I./ Meyer, M./ Ringle, C.M.:
Weighted regression segmentation: Schlittgen, R./ Ringle, C.M./ Sarstedt, M./ Becker, J.-M.:
HTMT: Henseler, J./ Sarstedt, M./ Ringle, C.M.
Uncovering heterogeneity and prediction-oriented segmentation: Becker, J.-M./ Rai, A./ Ringle, C.M./ Völckner, F.
The future of PLS-SEM! Sarstedt, M./ Ringle, C.M./ Henseler, J./ Hair, J.F.
Creating myths when chasing myths! Rigdon, E.E./ Becker, J.-M./ Rai, A./ Ringle, C.M./ Diamantopoulos, A./ Karahanna, E./ Straub, D.W./ Dijkstra, T.K.
The silver bullet! Hair, J.F./ Ringle, C.M./ Sarstedt, M.
منبع: محسن مرادی و آیدا میرالماسی
آکادمی تحلیل آماری ایران https://analysisacademy.com/
مشخصات
در این آموزش فرض بر اینه که Amos روی رایانه شما نصب شده است. اگر هنوز نرم افزار Amos را نصب نکردید، نرم افزار را نصب کنید و حتما مراحل را یک بار خودتان در نرم افزار انجام دهید. همچنین، تصور بر این هست که شما تجربه اساسی استفاده از برنامه های ویندوز را دارید. بدین معنی که شما می دانید که چگونه یک مورد را از منو انتخاب کنید، چگونه نشانگر ماوس را حرکت دهید، ماوس را کلیک کنید و دوبار کلیک کنید و …
پیش نیازها :
1-نصب نرم افزار Amos روی سیستم ویندوز
2-آشنایی با محیط ویندوز و کار با منوهای نرم افزاری
با مطالعه مطلب آموزش Amos می توانید :
1- با نرم افزار Amos به طور کامل آشنا شوید.
2- تحلیل آماری پایان نامه و یا مقاله تان را انجام دهید.
3- راه حل اشکالات و خطاهایی که در هنگام استفاده از نرم افزار اموس مشاهده می کنید؛ برطرف نمایید.
و …
پیش فرض های نرم افزار Amos
همونطور که میدونیم مهم ترین پیش فرض های انجام معادلات ساختاری در نرم افزار Amos به شرح زیر است :
- مناسب بودن تعداد نمونه ها
- رابطه خطی بین متغیرها
- عدم وجود کوواریانس با مقدار صفر در بین متغیرها
- عدم وجود همخطی بین متغیرها
- دیتاها بایستی از نوع فاصله ای باشند.
- نرمال بودن توزیع داده ها (گارسون، 2009)
آموزش رسم مدل معادلات ساختاری در نرم افزار Amos
آموزش رسم مدل در نرم افزار اموس
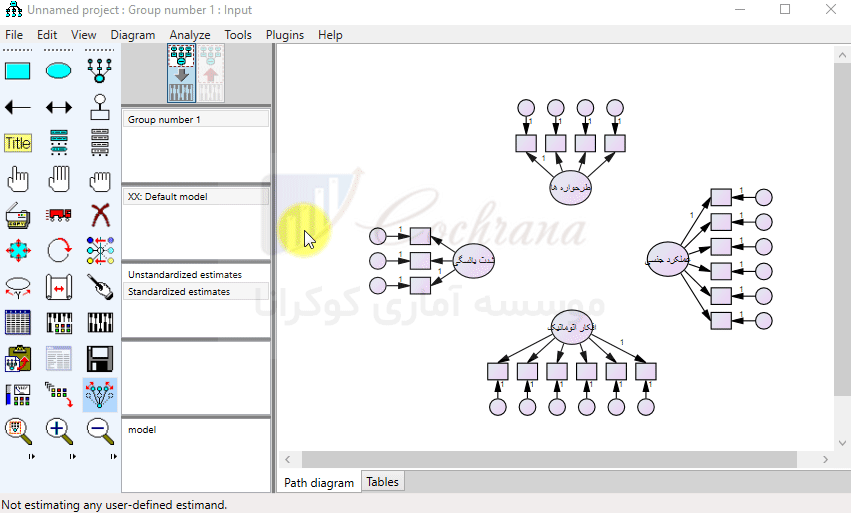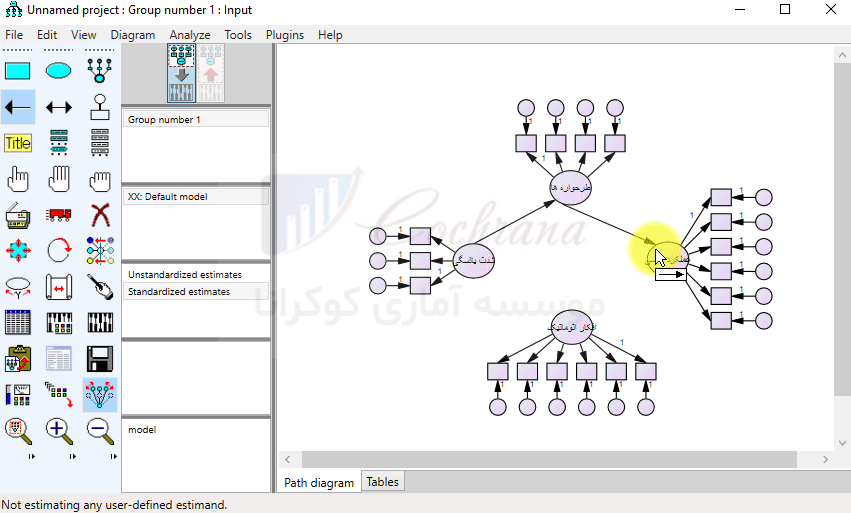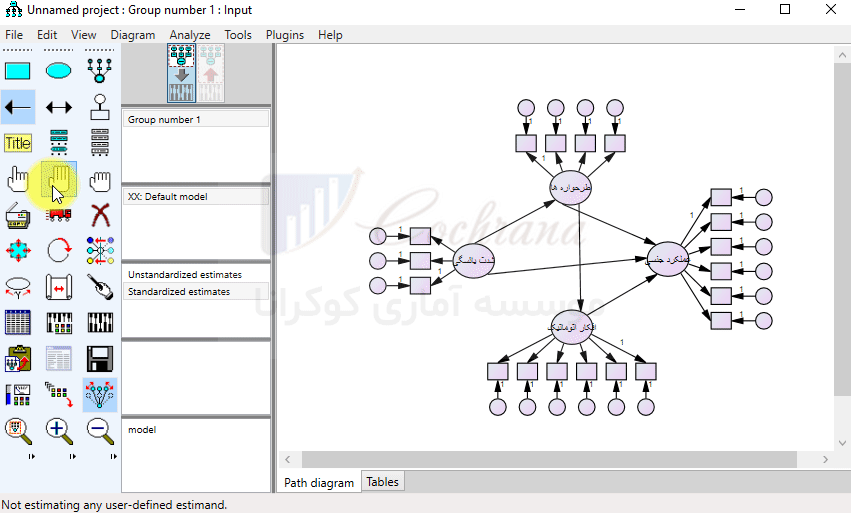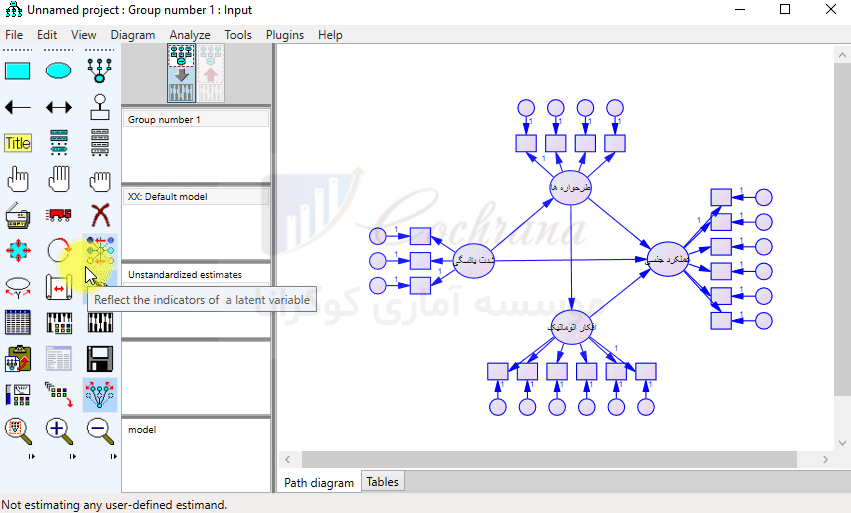
فرض کنید می خواهیم مدل معادلات ساختاری زیر را در نرم افزار Amos رسم کنیم :
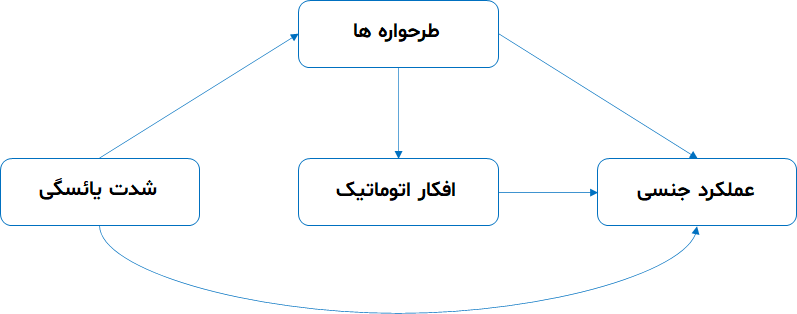
اولش لازمه که بدونیم هر متغیر چندتا گویه یا زیر مقیاس داره که این اطلاعات رو این پایین آوردم
گویه ها و زیر شاخص های متغیرها جهت رسم در نرم افزار Amos به شرح زیر است :
- زیر مقیاس های متغیر شدت یائسگی شامل : نشانه های جسمانی، نشانه های روانی و نشانه های ادراری
- زیر مقیاس های متغیر افکار اتوماتیک شامل : افکار سوء استفاده، بدنی، فقدان، ، انفعال، شکست
- زیر مقیاس های متغیر طرحواره ها شامل : نا مطلوبیت و طرد شدگی، بی کفایتی، خود ارزشمندی، تنهایی و درماندگی
- زیر مقیاس های متغیر عملکرد جنسی شامل : میل، تحریک، رطوبت، ارگاسم، رضایت و درد
برای رسم مدل معادلات ساختاری یاد شده مثل شکل زیر از طریق گزینه نشان داده شده تک تک متغیرهای تحقیق را رسم می کنیم. در این شکل با توجه به این که متغیر عملکرد جنسی دارای 6 زیر مقیاس است پس از انتخاب دکمه (Draw a latent variable) 6 بار بر روی صفحه سفید رنگ کلیک چپ می کنیم (تا بتونیم زیر مقیاس های مربوطه را بعدا جایگزین کنیم. در واقع الان داریم قالب متغیرها و زیر شاخص ها رو درست می کنیم.)
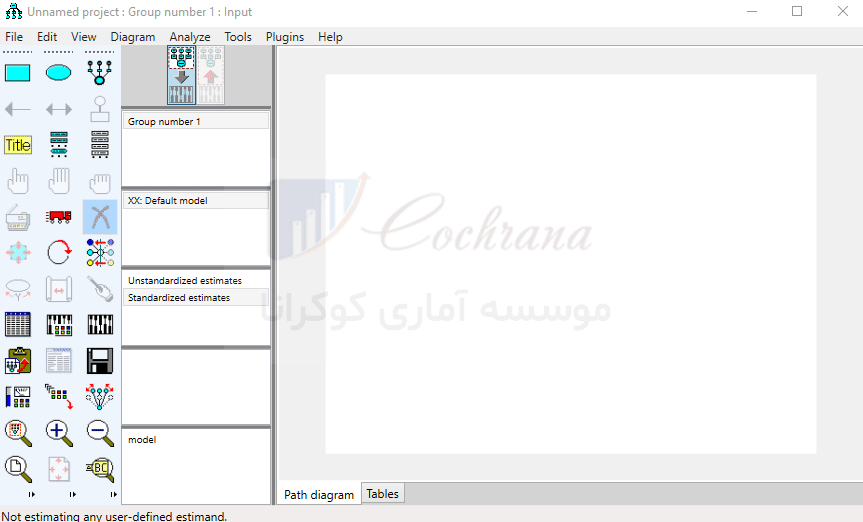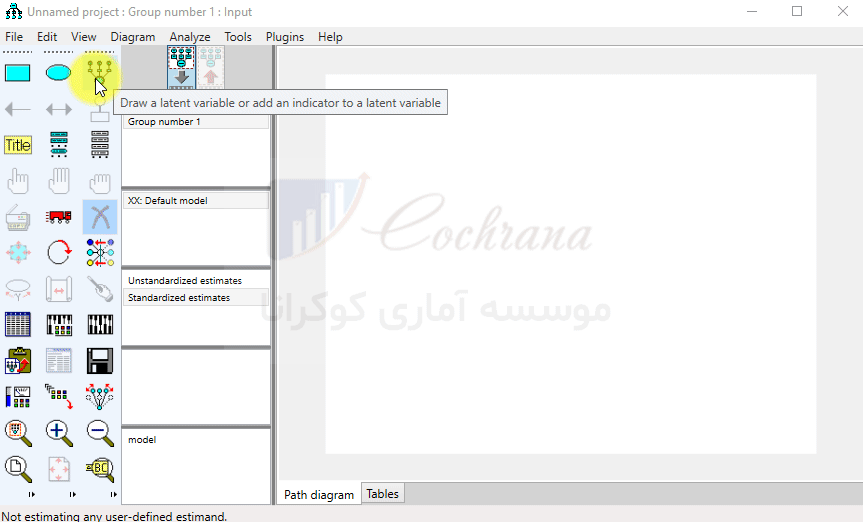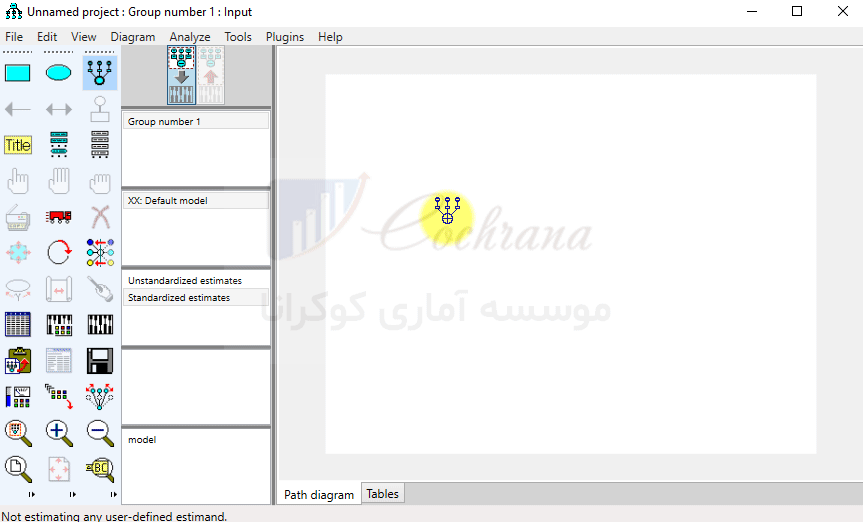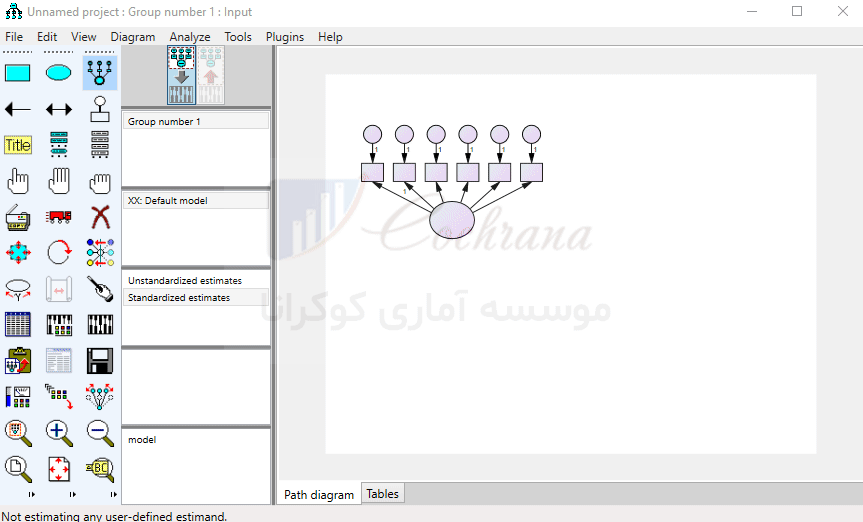
نحوه رسم متغیر پنهان به همراه متغیرهای آشکار
آموزش تصویری اموس (Amos)
مانند تصویر بالا تمام متغیرها را رسم می کنیم. برای این که جهت متغیرها رو تغییر بدیم می تونیم از دکمه (Rotate the indicators) استفاده کنیم. همچنین برای جا به جایی متغیرها می تونیم از دکمه (Move Objects) استفاده کنیم :
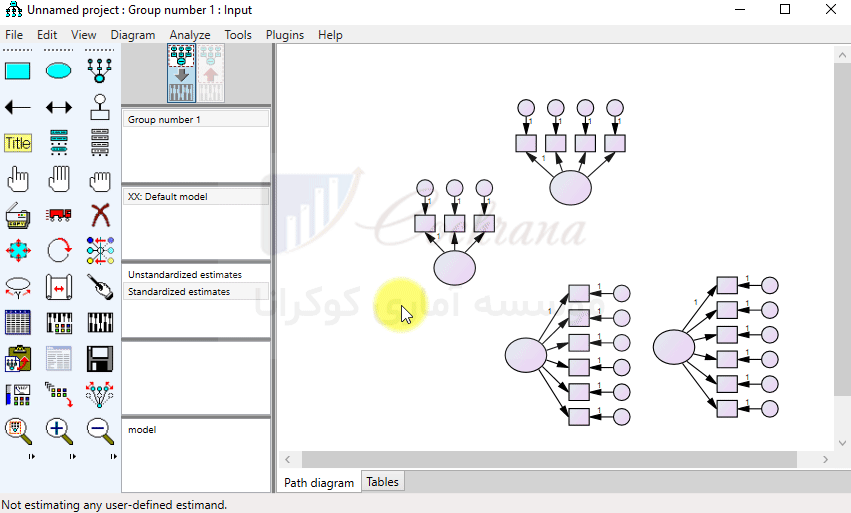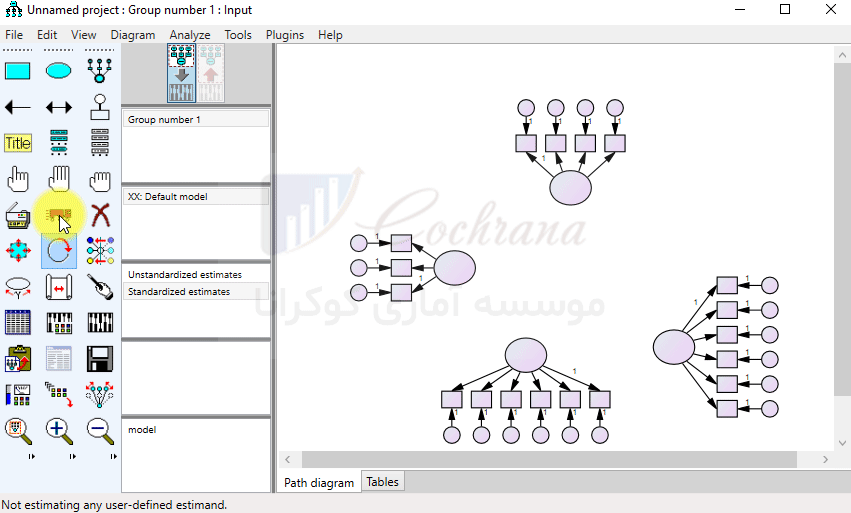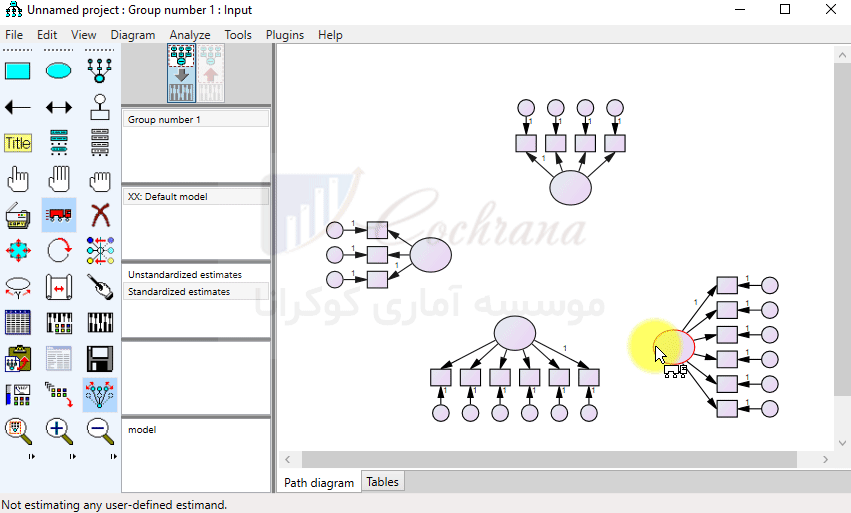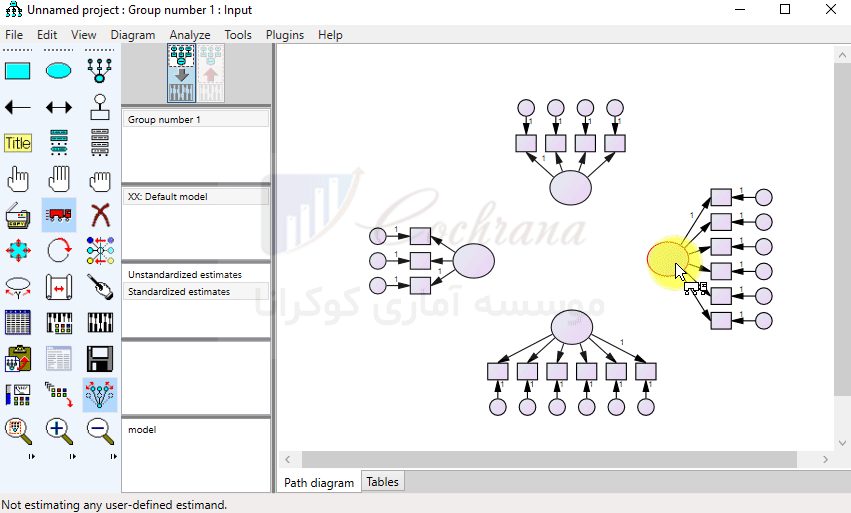
البته بهتره که برای جا به جایی متغیر پنهان با گویه های مربوط به خودش، دکمه (Preserve) را فعال کنیم تا با همدیگه قابلیت جا به جا شدن را داشته باشند. حالا وقتشه که اسم متغیرها رو مشخص کنیم. برای اینکار بایستی بر روی متغیر مورد نظر کلیک راست کرده و از منوی باز شده، گزینه (Object properties) را انتخاب کنیم. حال از طریق پنجره باز شده در کادر (Variable name)، به شرح زیر نامگذاری متغیرها رو انجام میدیم.
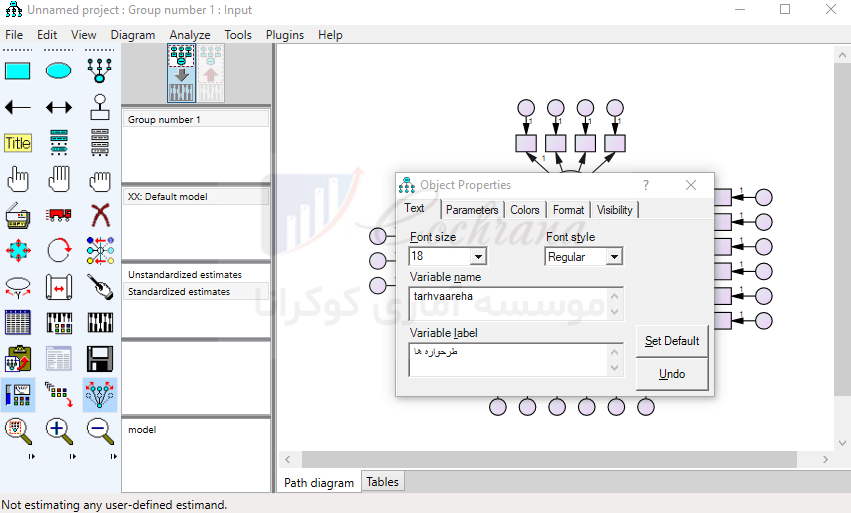
توجه داشته باشید که در کادر (Variable name) امکان درج حروف فارسی وجود ندارد. برای نامگذاری فارسی بایستی از کادر (Variable label) استفاده کنیم. این کار را برای تمام متغیرها انجام می دهیم. در ادامه با استفاده از دکمه (draw paths) جهت فلش ها را مشخص می نماییم.
پس از رسم پیکان ها در Amos می توان از طریق دکمه (Touch up a variable) (یا همون چوب جادویی خودمون) فلش های رسم شده را مرتب کرد. توجه داشته باشید که هنوز کار رسم مدل تموم نشده، مثل شکل زیر بایستی برای متغیرهایی که بهشون فلش وارد شده ارور بار تعریف کنیم. این کار رو با استفاده از دکمه (add a unique variable) انجام میدیم.
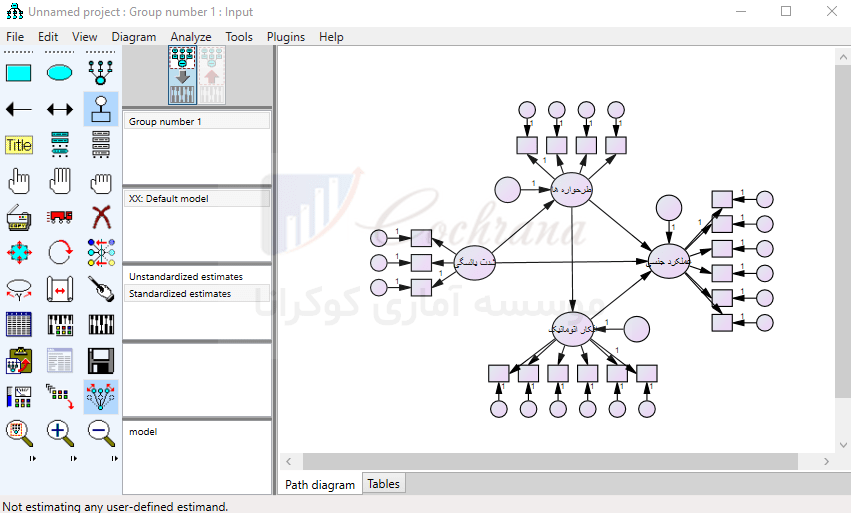
در حال حاضر رسم مدل نهایی شده و کافیه که زیر مقیاس ها و یا گویه های مربوطه رو برای هر شاخص تعریف کنیم. برای این کار لازمه که ابتدا دیتاهای مورد نظر را به نرم افزار معرفی کنیم.
نحوه ورود دیتا به نرم افزار Amos
نحوه ورود داده در نرم افزار اموس
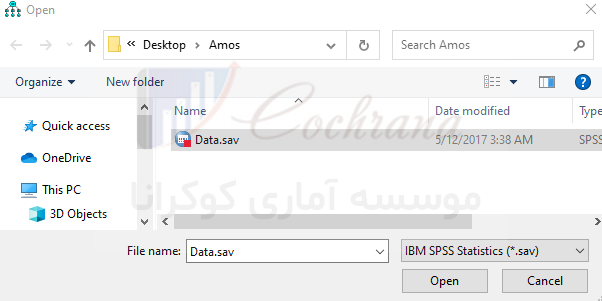
- در مرحله اول برای ورود دیتا بر روی گزینه (Select data file) همانطور که در شکل زیر نشان داده شده است کلیک کنید.
- در پنجره باز شده بر روی گزینه (File name) کلیک کنید.
- در پنجره جدید فایل دیتا مورد نظر با فرمت مخصوص SPSS (sav) را پیدا کرده و آن را انتخاب کنید.
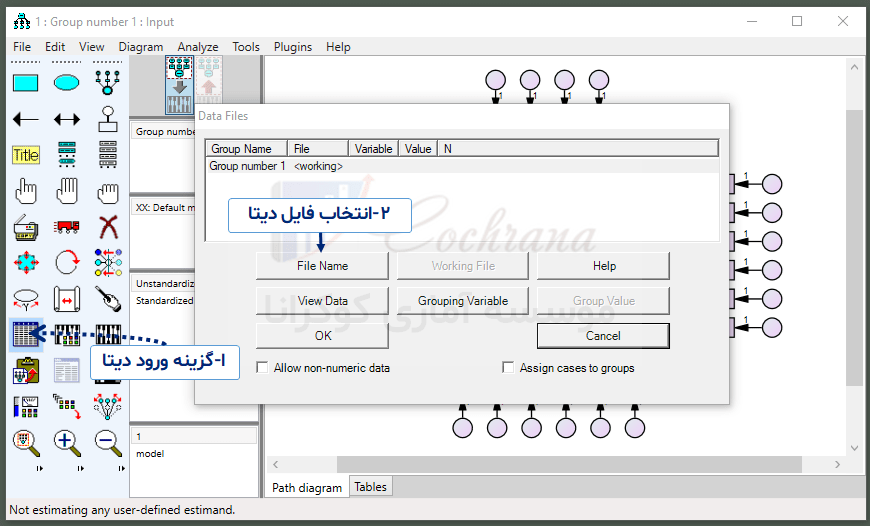
پس از انتخاب دیتای مورد نظر با فرمت گفته شده بر روی گزینه OK کلیک می کنیم. تا به صفحه اصلی نرم افزار AMOS برگردیم.
حال بر روی گزینه List Variables in Data set کلیک کرده و متغیرهای مورد نیاز را سر جای خود جایگذاری می نماییم.
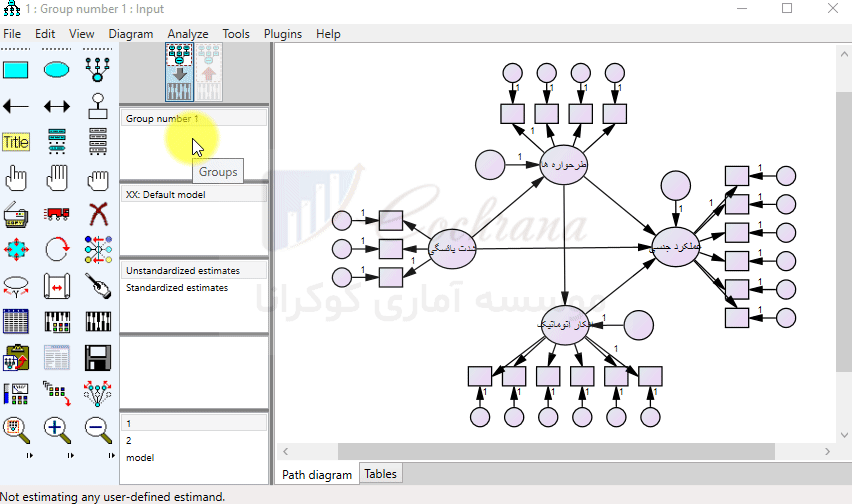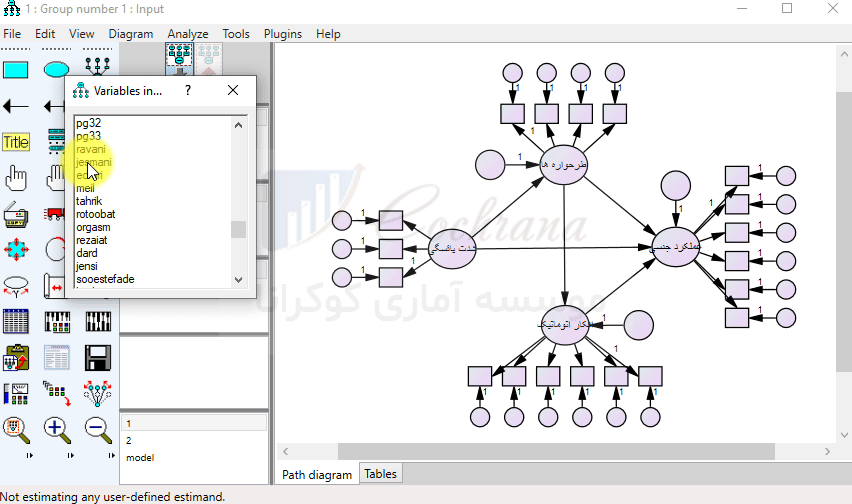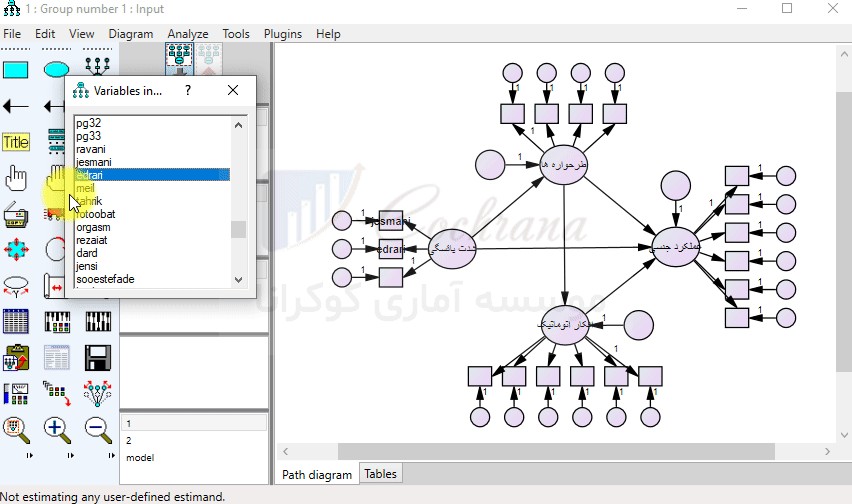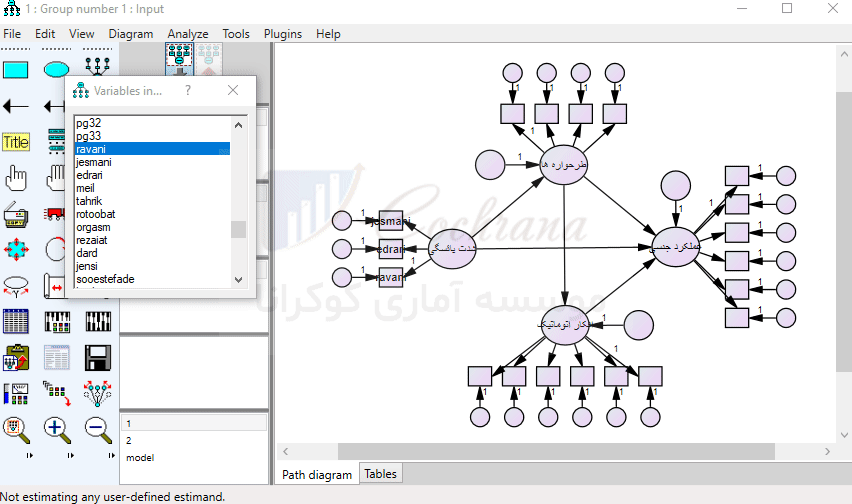
پس از این که تمامی متغیرها را در جای خود قرار دادیم. لازم است متغیرهای مربوط به خطاها نام گذاری شوند.
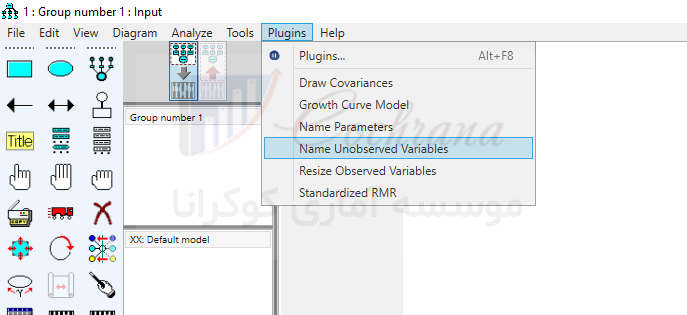
برای نام گذاری خودکار متغیرها از طریق منوی Plugins گزینه Name Unobserved Variables را انتخاب می کنیم. با انتخاب این گزینه متغیرهای بدون اسم، نام گذاری می شوند.
در شکل زیر مدل معادلات ساختاری مورد نظر پس از نام گذاری نهایی، ملاحظه می شود.
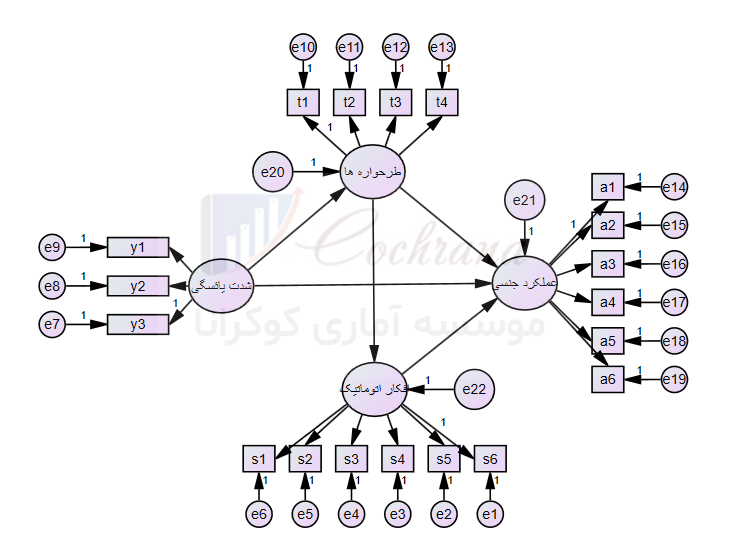
توجه داشته باشید که پس از قرار دادن متغیرهای موجود در داده ها در جای خود، به دلیل زیاد بودن طول نوشته متغیرها، از مخفف آنها در مدل استفاده کردیم. (ظاهر مدل با توجه به این که نوشته ها از کادرشون بیرون می زنند خراب میشه. البته می تونیم اندازه مستطیل و دایره ها را بزرگتر کنیم. اما بهتره که همیشه از مخفف متغیرها استفاده کنیم).
حال همه چیز آماده برای اجرای مدل و برآورد پارامترها می باشد.
منبع: موسسه آماری کوکرانا
مشخصات
پایایی ترکیبی با استفاده از فرمولی که توسط یورسکاگ ارائه شده نیز قابل محاسبه است. ضریب Rho نیز برای سنجش پایایی درونی سازهها است. همچنان که چین (۱۹۹۸) معتقد است ضریب Rho نسبت به آلفای کرونباخ از اطمینان بیشتری برخوردار است. به ضریب Rho گاهی ضریب دایلون-گولداشتین Dillon-Goldstein نیز گفته میشود. مقدار این ضریب باید بیش از ۰/۷ باشد. در نسخه شماره سه از نرم افزار Smart PLS این مقدار گزارش میشود.
منبع: کتاب مدلسازی معادلات ساختاری، نوشته آرش حبیبی، 1397
مشخصات
- یک سایت
- duplichecker
- businesssoftware
- hoshmandsaz
- فرمول منتور٫
- iranekade
- برنامه درسی در فضای مجازی
- خط روز | Rooz Line
- وطن اس ام اس
- mansari
- novin-dl
- وپ کید جدیدترین ها
- پارسي بلاگ سايت بيلدر
- دانلود سورس
- سرور سمپ زندگی مجازی کارول گیم
- تجزیه و تحلیل آماری داده های اقتصادی و صنعتی با مینی تب -sp
- دانلود کتاب pdf خلاصه کتاب جزوه
- زیر 100
- فروش-نوشتن پایان نامه کارشناسی فنی مهندسی ارزانتر -مدارت الکترونیک کامل بسته بندی برای مونتاژ
- dazardcasinobet
- تالار عروس
- nazanin
- خبر آن
- zhplus17
- xn--mgbajksoy90jca
درباره این سایت